Creating reliable, high-quality products in software development isn’t just a goal; it’s a necessity. Reliability metrics are a set of indicators that help developers, product teams, and companies understand how well a software application performs over time and how likely it is to meet user expectations. By monitoring these metrics, you can catch issues before they affect users, reduce system downtime, and make more informed development decisions.
In this article, we’ll cover 10 essential reliability metrics every software team should know by understanding what each metric means and learning practical ways to measure and apply them.
What are Reliability Metrics and Why do they Matter?
Reliability metrics are measurable indicators that help assess the stability, dependability, and overall quality of a software system. They evaluate the likelihood that a system will perform its intended functions without failure under specified conditions for a defined period. These metrics are essential for ensuring software quality, user satisfaction, and system dependability.
Why Reliability Metrics Matter
- Measure System Performance: Metrics help identify system weaknesses and areas for improvement.
- Enhance User Trust: Reliable software ensures a positive user experience and builds trust.
- Support Decision-Making: Reliability data guide developers and stakeholders in prioritizing fixes and updates.
- Reduce Downtime Costs: By monitoring metrics like MTTR and MTBF, organizations can minimize system downtime.
- Maintain SLA Compliance: Meeting reliability expectations ensures compliance with Service Level Agreements (SLAs).
10 Essential Reliability Metrics for Software Quality
Metrics are critical in measuring and improving software quality. They provide actionable insights into performance, reliability, and overall system health. Here are 10 essential reliability metrics that every software team should monitor:
1. Mean Time Between Failures (MTBF)
Mean Time Between Failures (MTBF) is a key reliability metric that measures the average time a system or component operates without experiencing a failure. It provides valuable insights into the stability and reliability of a system, helping teams predict the need for maintenance and plan accordingly.
MTBF is applicable to repairable systems where components can be fixed or replaced without replacing the entire system.
Why It's Important:
- Predictive Maintenance: MTBF enables teams to predict when failures are likely to occur and schedule maintenance proactively.
- System Health Assessment: A higher MTBF indicates better system health and fewer unexpected outages.
- Cost Avoidance: A higher MTBF can reduce downtime and its associated costs, improving revenue retention and customer trust.
Formula
To calculate MTBF, use the following formula:
MTBF = Total Operational Time ÷ Number of Failures
Where:
Total Operational Timerefers to the cumulative time the system has been functioning correctly without any interruptions.Number of Failuresis the total count of failures that have occurred over a specified period.
2. Mean Time to Failure (MTTF)
Mean Time to Failure (MTTF) measures the average time before a system or component fails. It helps us understand how reliable a software system is and estimate its expected lifespan before any failure occurs.
MTTF is applicable to non-repairable systems, such as hardware devices or certain software components, like microservices, APIs, or other modules within a system that aren’t meant to be fixed but rather replaced when they fail.
Why It's Important:
- Hardware Planning: MTTF helps determine replacement schedules for hardware and ensures timely upgrades or replacements to avoid unexpected failures.
- Risk Assessment: MTTF provides insight into the expected longevity of system components, helping to assess the risk of system outages.
Formula
To calculate MTTF:
MTTF = Total Operating Time ÷ Total of assets in use
Where:
Total Operating Timeis the total amount of time all assets have been operational.Total assets in use:The number of assets being measured.
3. Mean Time to Repair (MTTR)
Mean Time to Repair (MTTR) measures the average time it takes to restore a system or service after a failure. It reflects the efficiency of your operations and the ability of your team to resolve issues swiftly, minimizing the downtime and impact on users.
Why It's Important:
- Recovery Speed: MTTR directly reflects how quickly your team can respond to incidents and restore service.
- Minimizing Business Impact: A lower MTTR reduces downtime, which can otherwise disrupt business operations and result in financial loss.
- Operational Efficiency: MTTR can help you assess the effectiveness of your troubleshooting and repair processes.
Formula
MTTR can be calculated with the formula:
MTTR = Total maintenance time ÷ Number of repairs or replacements done
Where:
Total Maintenance Timeis the total amount of time spent on maintaining or repairing a system, typically measured in hours, minutes, or any unit of time consistent with the data being used.Number of Repairsis the total number of times the system has been repaired after a failure period.
4. Availability
Availability measures the percentage of time a system is operational and accessible to users. It directly indicates a system's stability and uptime, helping to answer questions like, “How often is my application ready for use?”.
Why It's Important:
- Business Continuity: Ensuring high availability helps guarantee that your services are accessible to users without interruption.
- Customer Satisfaction: High availability means minimal service disruptions, which keeps users happy and reduces churn.
- Compliance with SLAs: Availability is often included in SLAs, where service providers promise uptime to avoid penalties and maintain trust with clients.
Formula
To calculate availability, use:
Availability (%) = (Uptime / (Uptime + Downtime)) × 100
Where:
Uptime= Total time the system was operationalDowntime= Total time the system was not operational (unavailable)
Alternatively, you can calculate availability in terms of mean time metrics:
Availability (%) = MTBF / (MTBF + MTTR)
Where:
MTBF(Mean Time Between Failures)is the average time the system works before failingMTTR (Mean Time to Repair)is the average time it takes to repair the system after failure
5. Uptime
Uptime is the measure of the total time a system, application, or service is operational and accessible to users without any interruptions. It represents the reliability and stability of a system over a specific period. Uptime is often expressed as a percentage, providing a straightforward way to quantify system availability and performance.
Why It's Important:
- User Experience: High uptime ensures consistent access to services, which improves user satisfaction and trust.
- Business Continuity: For businesses, prolonged downtimes can lead to revenue losses, operational disruptions, and damage to brand reputation.
- Performance Benchmark: Monitoring uptime over time helps teams identify and address systemic issues, ensuring long-term reliability.
Formula
To Calculate UpTime use this formula:
Uptime (%) = (Total time – Downtime) / Total time * 100
Where:
Total Timeis the total duration under observation, which includes both the time the system was operational and the time it was unavailable (downtime).Downtimerefers to the period during which the system was not functioning or was inaccessible. This includes outages, system crashes, or scheduled maintenance.Uptime (%)is a ratio that shows how much of the total time the system was operational, expressed as a percentage.
6. Error Rate
Error rate measures how frequently errors occur within a system over a set period. It is particularly critical for real-time systems, where even minor errors can cause significant disruptions.
Why It's Important:
- Proactive Troubleshooting: High error rates indicate that there may be systemic issues affecting the stability of the system.
- User Experience: A high error rate can result in frustrating user experiences, leading to churn or reduced customer satisfaction.
- System Predictability: Monitoring error rates helps ensure that the system remains reliable and predictable.
Formula
To calculate error rate, use:
Error Rate = (Number of requests with errors ÷ Total number of requests) × 100%
Where:
Number of requests with errorsrefers to the total number of requests that resulted in errorsTotal number of Requestsis the total number of transactions or requests processed by the system.
7. Defect Density
Defect density is the number of defects (bugs) found in a software system relative to the size of the codebase. This metric is used to assess the quality of the code, identify problematic areas, and prioritize testing and fixes.
Why It's Important:
- Quality Indicator: High defect density may indicate poorly written code or lack of thorough testing.
- Prioritization of Refactoring: Teams can use defect density to pinpoint areas that need refactoring to improve overall software quality.
- Testing Efficiency: A higher defect density could signal the need for more targeted testing in the affected code areas.
Formula
To calculate defect density, use the following formula:
Defect Density = (Total Defects / Total Lines of Code) × 1000 (per KLOC)
Where:
Total Defectsis the total number of defects identified.Total Lines of Code: The total number of lines of code in the software.KLOC: Represents thousands of lines of code (1 KLOC = 1000 lines of code).
8. Failure Rate
Failure rate measures how often failures occur in a system over a given period. This metric provides insights into the stability of the system and the likelihood of service interruptions.
Why It's Important:
- Predicting Failures: A higher failure rate signals a need for system improvements to reduce instability.
- Root Cause Analysis: Failure rate analysis helps identify common patterns or recurring issues, allowing teams to pinpoint underlying causes.
- System Optimization: By tracking failure rates, teams can continuously improve the system’s performance and reduce the likelihood of future failures.
Formula
To calculate the failure rate, use the following formula:
Failure Rate = Number of Failures ÷ Total Operating Time
Where:
Number of Failuresis the total number of failures observed.Total Operating Timeis the total time the system was in operation.
9. Probability of Failure on Demand (POFOD)
Probability of Failure on Demand (POFOD) measures the likelihood that a system will fail when a specific demand or request is made. It is a probabilistic metric, often expressed as a percentage or decimal, indicating the reliability of a system to perform correctly under a single operation or request.
Why It's Important:
- Critical for High-Stakes Systems: POFOD is crucial for systems where even a single failure could have catastrophic consequences, such as air traffic control software or medical equipment.
- Risk Assessment: It provides a quantitative measure to assess the risks of failure, which helps to prioritize system improvements and redundancy strategies.
- Decision Support: It Helps organizations decide on acceptable levels of risk, ensuring that systems meet regulatory standards and user expectations.
Formula
To calculate the Probability of Failure on Demand , use the following formula:
POFOD = 1 / MTBF
Where:
MTBFrepresents the average time a system operates before experiencing a failure.
OR
POFOD = R / T
Where:
R: Total number of failures observed in a given timeframe.T: Total operational time during that period.
10. Customer-Reported Defects
Customer-reported defects serves as a vital indicator of reliability which offers direct insights into how users experience the product. This metric provides an unfiltered view of what might be slipping through internal testing, highlighting issues that directly impact users.
Why It's Important:
- User Feedback: Customer-reported defects offer direct insights into how the product performs in the real world, ensuring that internal tests are aligned with actual user experiences.
- Quality Assurance: Addressing these defects improves user satisfaction and helps build a trustworthy product.
- Continuous Feedback Loop: By actively monitoring and fixing customer-reported defects, teams can ensure the software continues to meet users’ evolving needs.
Formula
To calculate customer-reported defects, use:
Customer-Reported Defects Rate = Total Customer-Reported Defects ÷ Total Customer Interactions or Sessions * 100
Where:
- Total Customer-Reported Defects: The total number of defects or issues reported by customers.
- Total Customer Interactions or Sessions: The total number of interactions or sessions customers had with your product, service, or system.
How to Choose the Right Reliability Metrics
Choosing the right reliability metrics is crucial for any organization that aims to ensure high availability, performance, and stability in its systems. However, with so many available metrics, selecting the ones that align with your goals and the needs of your organization can be challenging. Here's a guide on how to choose the right reliability metrics:
1. Define Your Reliability Objective
The first step in selecting the right metrics is to understand what you want to achieve with reliability. Are you focused on minimizing downtime? Do you need to improve response times? Is your focus on customer satisfaction, or on operational efficiency? Your reliability goals will directly influence the metrics you track. Some common objectives include:
- Availability: Ensuring systems are up and running.
- Performance: Ensuring systems perform at optimal speed and efficiency.
- Resilience: Ensuring systems can recover quickly from failures.
- Scalability: Ensuring systems can handle growth in traffic or data.
2. Match Metrics to Your Goals
Once you have defined your objectives, choose the metrics that directly support them. For instance:
- If minimizing downtime is critical, focus on
Availability,Mean Time Between Failures (MTBF), andMean Time to Repair (MTTR). - For enhancing user experience, prioritize metrics like
Error Rates,Response Times, andCustomer-Reported Defects. - When targeting operational efficiency, consider
Failure RateandDefect Density.
3. Set Clear, Measurable Targets
With metrics selected, establish clear and achievable targets to track progress. Start with a few key metrics, especially if your team is new to reliability tracking, to avoid overwhelming them with too much data. Strategic simplicity prevents overwhelming your team with excessive data.
Consider the following when setting targets:
- Set realistic, incremental goals. Aim for gradual improvements rather than large, unattainable leaps.
- Create benchmarks based on industry standards or historical data.
- Align targets with broader organizational key performance indicators (KPIs)
4. Select the Right Tools for Data Collection
The effectiveness of your metrics depends on data quality and collection methods. Choose tools that:
- Seamlessly integrate with your existing infrastructure
- Provide real-time, accurate data collection
- Support automated reporting and analysis
- Allow easy visualization and interpretation of metrics
- Ensure data privacy and security
5. Embed Metrics into Your Workflow
To make metrics actionable, integrate them into your daily workflow. This means:
- Consistently monitoring and analyzing metric trends
- Incorporating metric insights into team discussions and decision-making
- Creating regular review cycles to assess metric performance
- Establishing clear accountability for metric improvement
- Developing responsive strategies based on metric insights
Challenges in Capturing and Interpreting Reliability Metrics
When it comes to measuring software reliability, capturing and interpreting metrics can be as complex as it is valuable. Here are some common challenges and how they can be addressed:
1. Inconsistent Data Collection
When reliability metrics are not collected consistently across all system components, the data may become unreliable. For instance, tracking Mean Time to Repair (MTTR) for only part of your infrastructure can skew your view of system downtime, leading to misinformed decisions.
Solution: Standardize your data collection process across all system components. Set clear guidelines for how, when, and where to measure each metric to ensure that everyone on your team follows the same procedures.
2. Incomplete or Missing Data
Gaps in data can occur in large or complex systems, leading to incomplete insights into reliability. For example, if certain metrics, like error rates, aren’t tracked in specific environments, your data might not reflect the full picture.
Solution: Identify critical data sources for each metric and implement redundant tracking. Use multiple tools or methods to gather key data, and set up automated alerts for missing or incomplete data. This way, you can proactively fill data gaps to ensure completeness.
3. Misinterpreting Metrics Due to Lack of Context
Metrics often need context to be properly understood. For instance, a high defect density might be acceptable during early testing but problematic in a production environment. Without knowing what’s normal for your specific stage or environment, interpreting these metrics can be misleading.
Solution: Establish benchmarks for each metric based on your project's needs and stages. This will help you understand what the data should look like at various stages or environments and give you a clearer idea of when a metric is truly concerning.
4. Over-focusing on a Single Metric
Concentrating on one reliability metric while neglecting others provides an incomplete and potentially misleading system health assessment. No single metric can comprehensively represent overall system reliability.
Solution: Track a balanced set of 3-5 key metrics that represent different aspects of system reliability. These should include factors such as availability, performance, error rates, and recovery times. This provides a more holistic view of your system's health.
5. Balancing Multiple Metrics
Reliability metrics are often interrelated. For example, a high MTTR might explain a drop in availability, but these relationships can be difficult to see if metrics are interpreted in isolation. Balancing and combining these metrics is essential for accurate insights.
Solution: Define how your metrics relate to one another and track them together. Create visual dashboards to display multiple metrics side by side, making it easier to spot patterns and correlations. Regularly review these metrics with cross-functional teams to ensure you’re getting a complete picture of your system’s reliability.
Observability Tools for Enhanced Reliability Monitoring
SigNoz provides powerful capabilities for monitoring and analyzing application performance, making it an ideal solution for tracking software reliability metrics. With its robust observability features and seamless integration with OpenTelemetry, SigNoz empowers teams to proactively manage system reliability and improve software quality.
Here's how SigNoz stands out:
Unified Observability: With SigNoz, you get logs, metrics, and traces all in one platform. This centralization is crucial for understanding reliability metrics, as it lets you see the entire picture of your application’s performance.
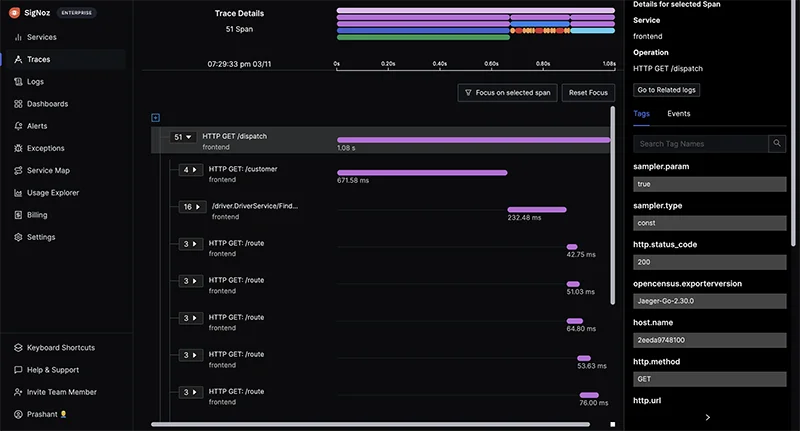
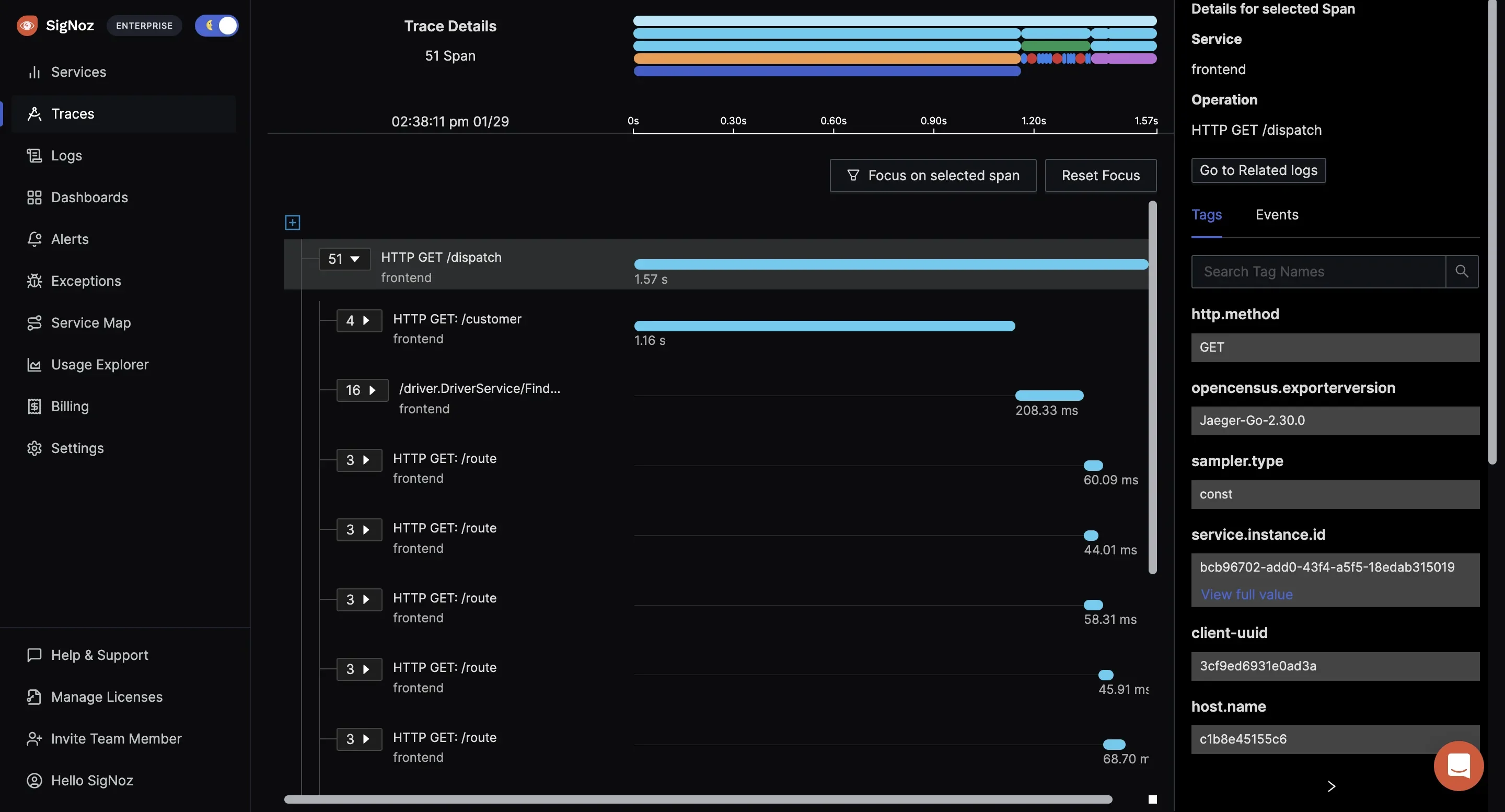
A clear picture of a SigNoz Dashboard showing logs, metrics and traces on a single platform Distributed Tracing: SigNoz allows you to trace requests across various microservices, making it easier to pinpoint exactly where an issue occurred. This feature is particularly valuable for teams working with complex architectures, as it helps track metrics like Mean Time to Repair (MTTR) by identifying the root cause of issues quickly.
Spans of a trace visualized with the help of flamegraphs and gantt charts in SigNoz dashboard Customizable Dashboards: SigNoz enables you to create dashboards tailored to the reliability metrics you care about most, such as availability, error rates, or defect density. These dashboards give you at-a-glance insights into your application’s health, so you can make data-driven decisions.
Alerting and Notifications: You can set up alerts based on specific thresholds or events, such as a spike in error rates or a drop in availability. This feature ensures that you’re always aware of potential issues and can address them before they escalate, improving metrics like MTBF (Mean Time Between Failures).
OpenTelemetry Integration: SigNoz uses OpenTelemetry, an open-source observability framework, which makes it compatible with many programming languages and frameworks. This integration helps in capturing data for reliability metrics across various parts of your application without extensive configuration
SigNoz cloud is the easiest way to run SigNoz. Sign up for a free account and get 30 days of unlimited access to all features.

You can also install and self-host SigNoz yourself since it is open-source. With 19,000+ GitHub stars, open-source SigNoz is loved by developers. Find the instructions to self-host SigNoz.
Implementation Guide: Integrating SigNoz into Your Reliability Monitoring Process
Here’s a step-by-step guide on setting up SigNoz to enhance your reliability monitoring:
Step 1: Create a SigNoz Cloud Account
- Sign up here, enter your email address, password, and other required details.
- Log In to the SigNoz Cloud Dashboard
Step 2: Connect Your Application to SigNoz Cloud
To connect to SigNoz Cloud, you need an Ingestion Key. Navigate to the
Settingspage in the SigNoz UI and click on theingestion settings Tabto generate youringestion key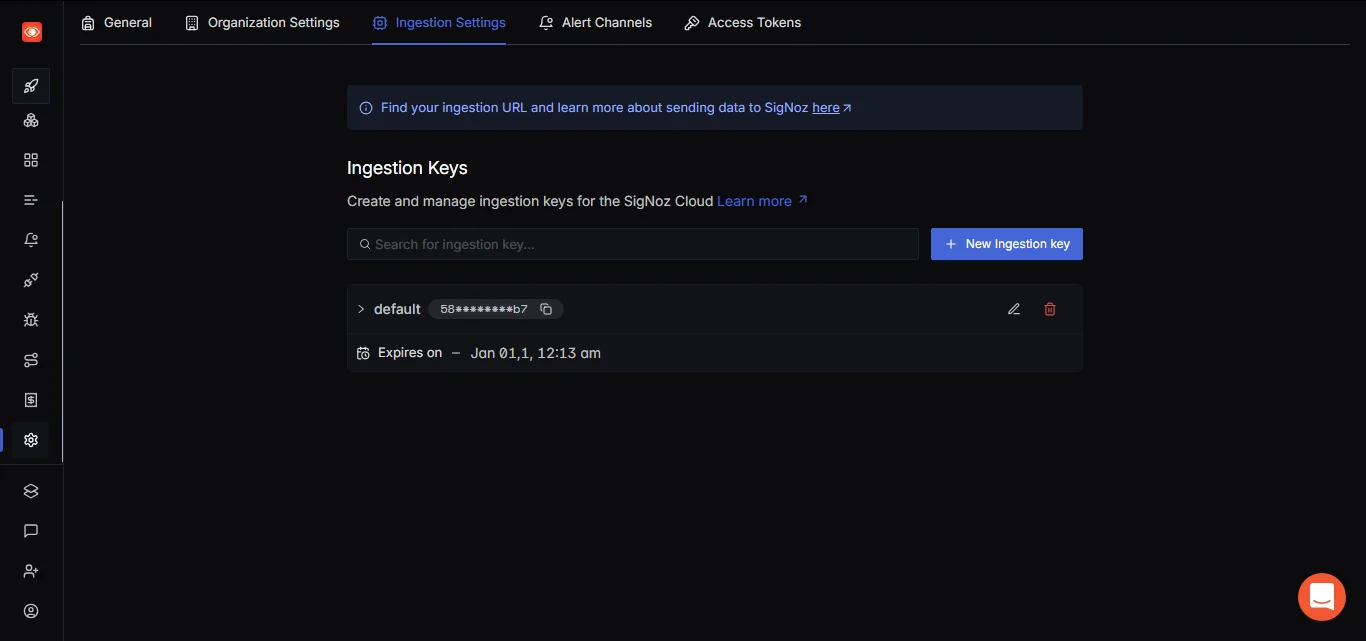
SigNoz UI showing the ingestion settings Tab
Step 3: Instrument Your Application
SigNoz Cloud supports OpenTelemetry for instrumentation. To illustrate, let’s explore how to instrument a Node.js application, as detailed in this article:
Install OpenTelemetry package:
npm install --save @opentelemetry/api npm install --save @opentelemetry/auto-instrumentations-nodeStart the application on your terminal in order to generate the data(Your Request and Response Data) that needs to be sent to SigNoz cloud.
export OTEL_TRACES_EXPORTER="otlp" export OTEL_EXPORTER_OTLP_ENDPOINT="<YOUR_SIGNOZ_ENDPOINT>" export OTEL_NODE_RESOURCE_DETECTORS="env,host,os" export OTEL_SERVICE_NAME="<YOUR_APP_NAME>" export OTEL_EXPORTER_OTLP_HEADERS="signoz-ingestion-key=<YOUR_INGESTION_KEY>" export NODE_OPTIONS="--require @opentelemetry/auto-instrumentations-node/register" <your_run_command>Note: Replace
<your_run_command>with the run command of your applicationRestart your application to start sending data to SigNoz.
Step 4: Explore SigNoz Cloud Dashboard
Once your application is connected, the SigNoz Cloud dashboard starts displaying telemetry data. Here’s how to analyze key reliability metrics:
Click on the Traces tab to see a detailed log of application requests & performance data.

SigNoz Cloud UI showing request data on the trace section Use filters to analyze specific endpoints or services.

A Trace Explorer showing traces based on time and other filters Navigate to the Exceptions section to identify and analyze application errors.
Drill down into specific errors to understand their root causes.

SigNoz Cloud UI showing Exceptions section Open the Metrics section to track request latency across endpoints.
Identify bottlenecks and optimize slow-performing API.

Overview of the Metrics section
Step 5: Set Up Alerts
SigNoz allows you to configure alerts for proactive monitoring. Here’s how to set up an alert for high error rates:
Go to the "Alerts" section.
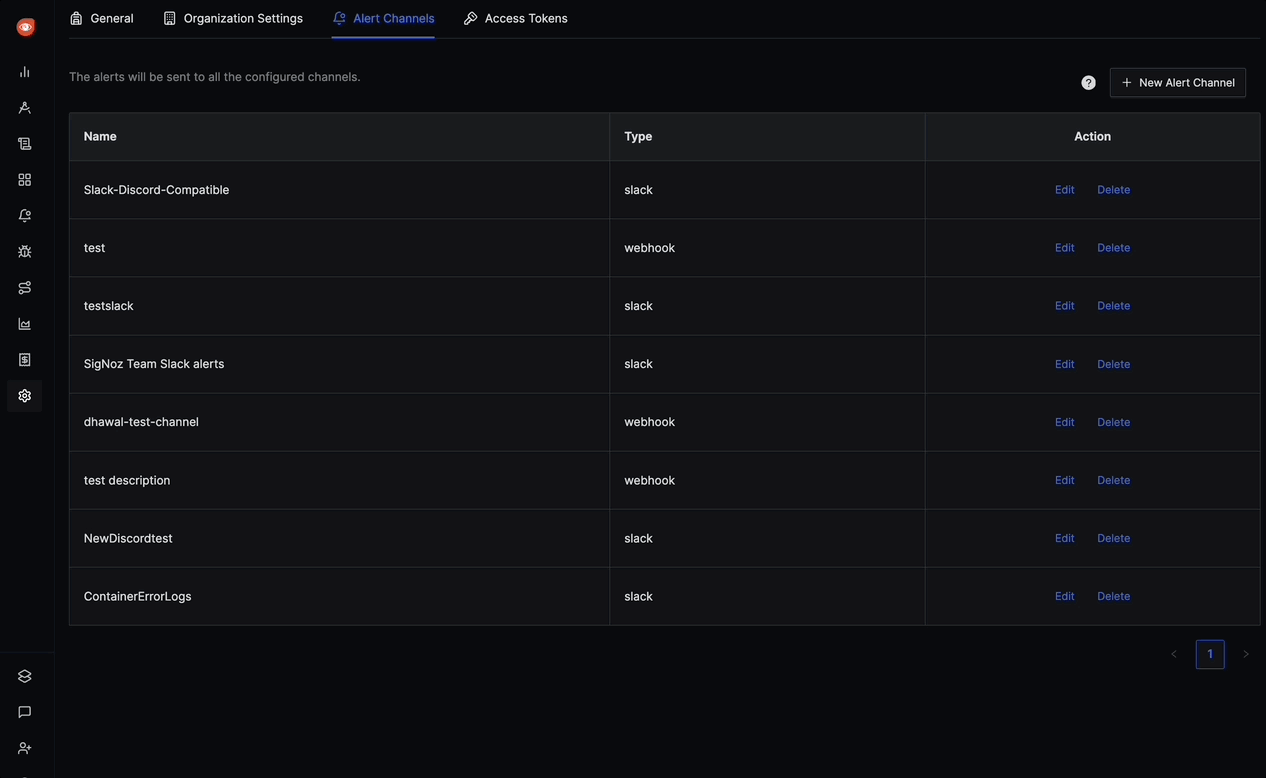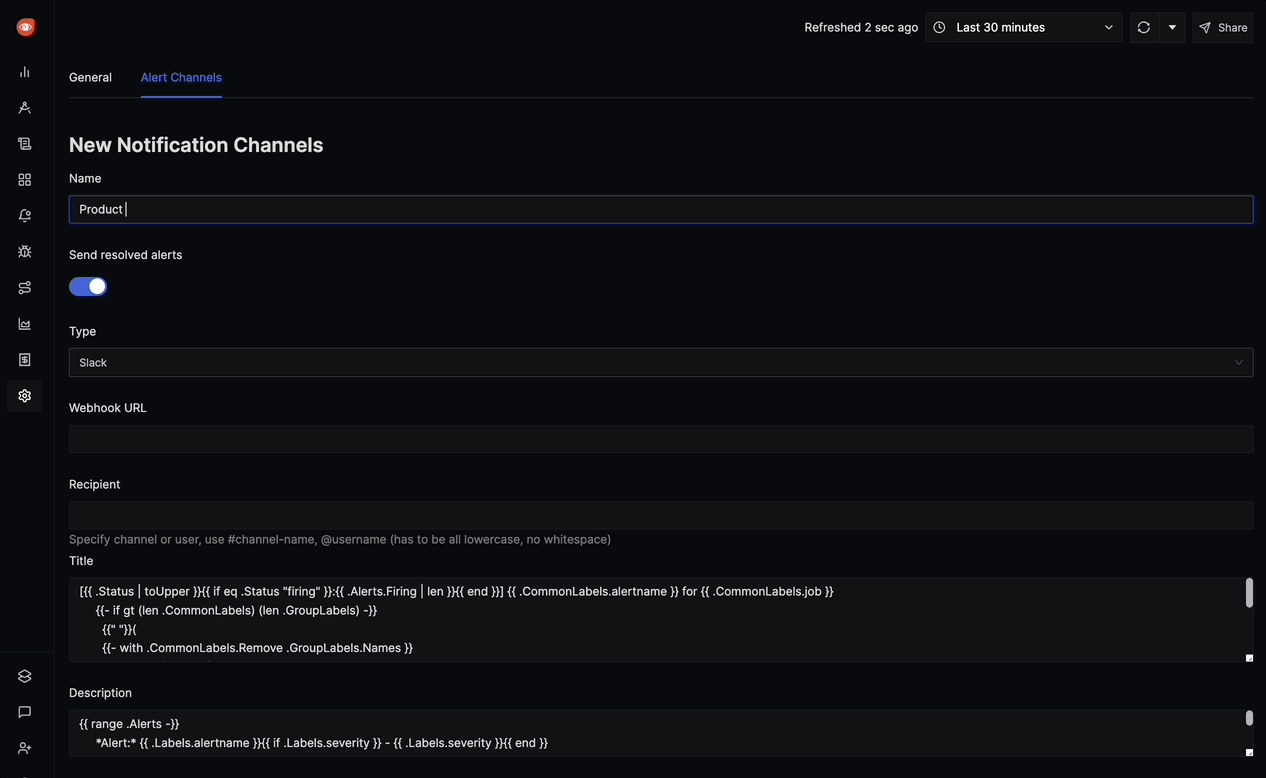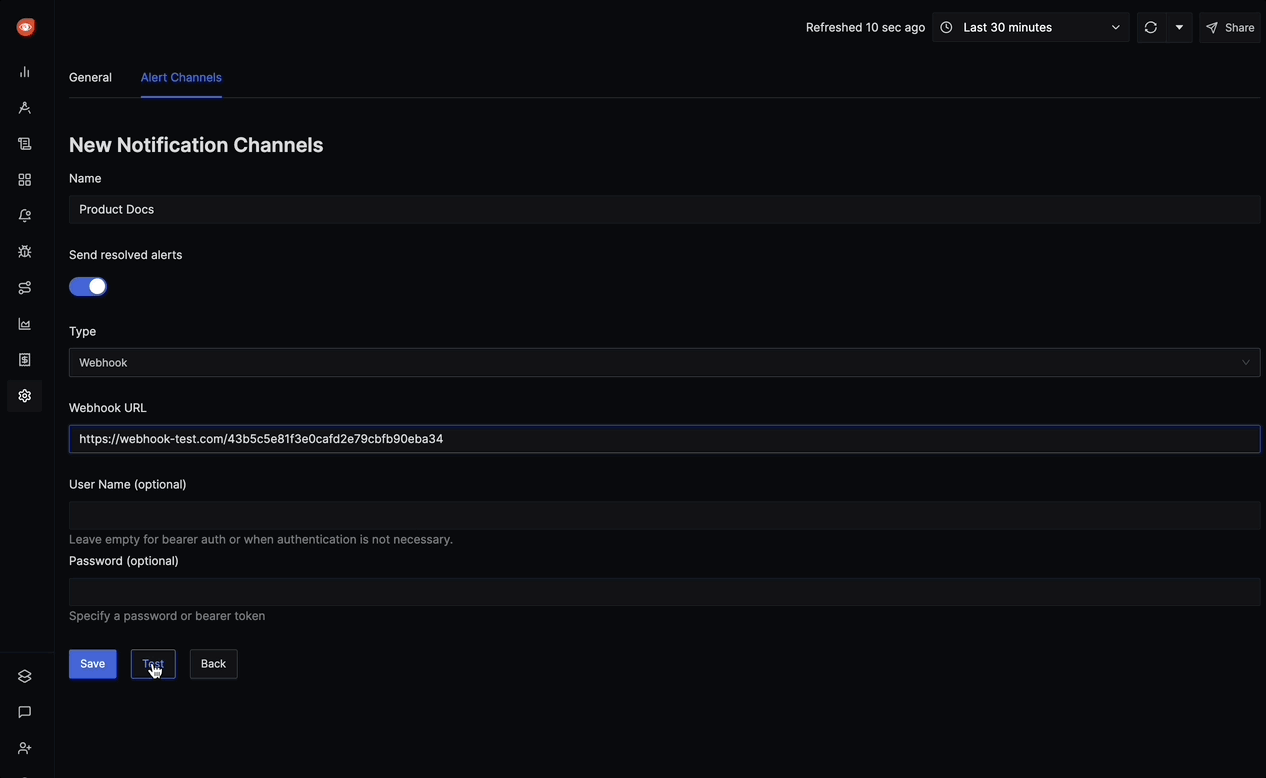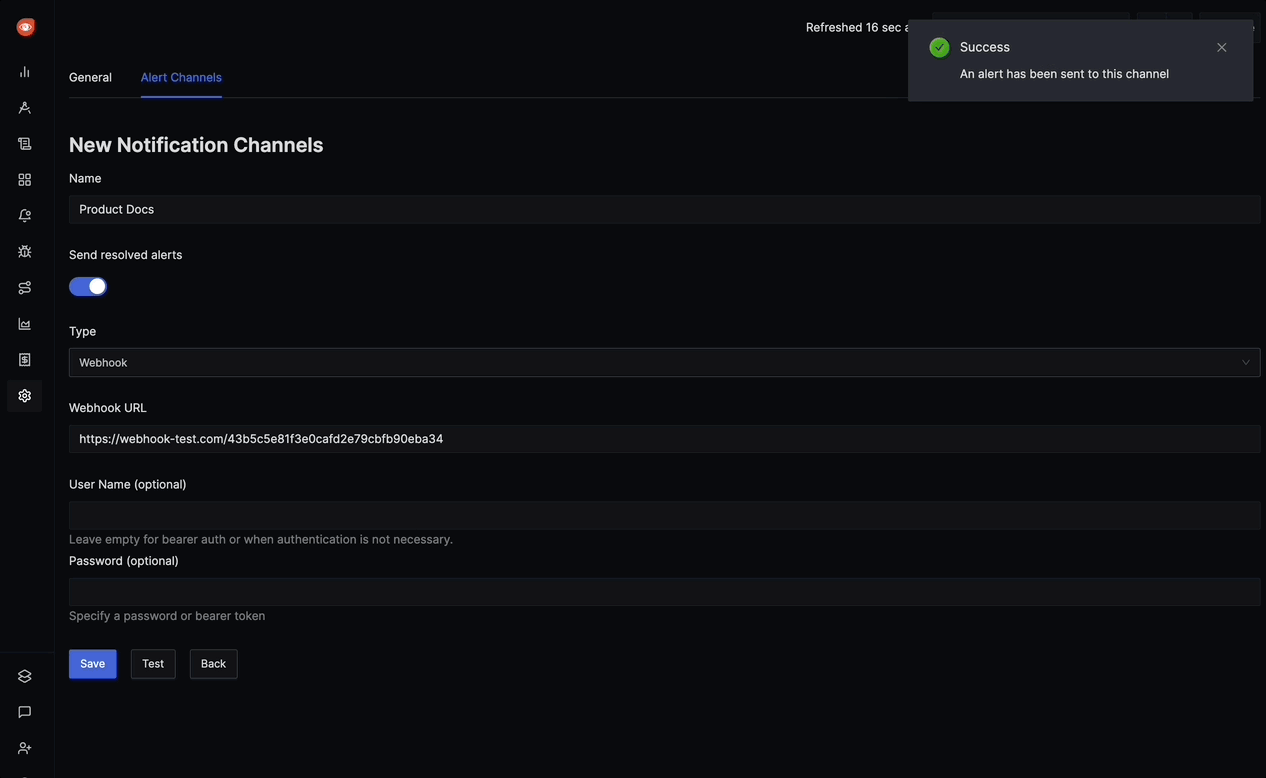
Create a new alert and specify:
- Condition: Error rate > 5%.
- Notification: Email or Slack integration.
Save the alert and test it with sample data
A short demo on how to navigate the Alert section
Advantages of SigNoz Over Traditional Monitoring Tools
SigNoz stands out from traditional monitoring tools for several reasons, particularly for teams aiming to optimize reliability metrics:
- End-to-End Observability: While traditional tools might offer either logging or tracing, SigNoz provides full observability by combining logs, traces, and metrics. This integration makes it easier to gain a holistic view of your application’s reliability.
- Cost-Effectiveness: Being open source, SigNoz avoids the licensing costs associated with many proprietary tools, making it accessible for projects with tight budgets.
- Customizability: SigNoz’s open-source nature allows for deep customization. Teams can tailor the platform to their specific needs, whether that means creating custom dashboards, setting unique alert conditions, or integrating it with existing DevOps workflows.
- Vendor Independence: Many traditional tools lock you into their ecosystem, but SigNoz, powered by OpenTelemetry, is vendor-neutral. This flexibility allows you to switch out components or make adjustments without being dependent on a single provider
Future Trends in Software Reliability Metrics
As software systems grow more complex, several key trends are emerging in software reliability metrics:
- Emerging Metrics for Modern Architectures
- Metrics tailored for microservices, such as request latency and service dependency errors.
- Serverless-specific metrics, like cold start time and invocation success rate.
- AI & Machine Learning in Reliability
- Predictive analytics for forecasting system failures and reducing downtime.
- Anomaly detection algorithms for real-time issue identification.
- AI-powered self-healing systems that automate corrective actions.
- Evolving Industry Standards
- Shift toward continuous reliability testing for ongoing stability validation.
- Inclusion of user-centric and security-integrated metrics in reliability assessments.
- Updates to global standards (e.g., ISO, IEEE) to align with modern practices.
Key Takeaways
- Reliability metrics provide a roadmap to improve software quality and user satisfaction.
- Continuous monitoring helps identify trends and issues before they escalate.
- Use a combination of metrics for a comprehensive view.
- Use modern tools like SigNoz to simplify monitoring and enhance visibility into system performance.
- Focus on continuous improvement to maintain high reliability.
FAQs
What is the difference between reliability and availability?
Reliability focuses on how consistently a system performs without failure over time while availability measures the percentage of time a system is operational and accessible.
How often should reliability metrics be reviewed?
The frequency of reviewing reliability metrics varies based on system criticality and organizational needs. Critical systems often require daily or real-time monitoring, while standard applications typically benefit from weekly reviews. Long-term trend analysis can be conducted monthly or quarterly, adapting to the specific requirements of the software and business context.
Can reliability metrics be applied to all types of software systems?
Reliability metrics can be applied to most software systems, though their implementation and interpretation will vary. Different system types require tailored approaches to tracking and analyzing reliability, considering their unique characteristics and operational constraints.
How do reliability metrics impact the software development lifecycle?
Reliability metrics help to set performance goals in the planning phase, identify and resolve issues during development phase, track system availability and performance in deployment phase, and drive continuous improvement through metrics like MTTR in the maintenance phase.
